Using our survey database, we tested several popular approaches for conducting pay equity analyses to determine which models yield more accurate and actionable insights to drive sustainable change.
Closing gender and ethnicity-based pay gaps is increasingly required by law in much of the world, and as a result, many companies now conduct proactive pay equity analyses each year to mitigate their legal risks. While this makes sense, legal considerations are not the only reason to address pay gaps. First and foremost, it is the right thing to do. Additionally, creating fairer and more transparent compensation programs boosts employee morale, establishes stronger links between pay and performance and makes companies a more attractive place to work for all.
However, when it comes to pay equity, meeting legal requirements and designing effective compensation policies do not always go hand-in-hand. In our experience, over-rotating toward legally-driven pay equity approaches can fall short of establishing sustainable pay fairness, and at the same time, overly analytical methods do not always address legal requirements.
To illustrate this dynamic, and to help companies appropriately balance both sides of the equation, we examined millions of employee records from our Radford survey database using multiple statistical methods. These methodologies included the most rigorous analytical approaches and tools commonly used by law firms and compensation consultants when supporting clients. Different methodologies yield different results, which can have a profound impact on the policy choices companies ultimately make.
Understanding Your Methodology Choices
Before diving into the data, let’s first do a quick review of common pay equity methodologies. Fortunately, what is not in dispute is the notion that effective pay equity analyses require the use of multivariate regression models. In short, multivariate regression analysis is a well-established statistical methodology that can take multiple factors into account “simultaneously” when determining if pay levels by gender or ethnicity are equal.
By controlling for many different legitimate business factors (e.g., grade level, job family group, tenure) at once, the model can determine the impact of any one factor while holding all other factors constant. For example, what is the impact of one year of added tenure on pay when you filter out the fact that more tenured people also tend to be older? In addition, multivariate regression models provide statistics that indicate if a found pattern — such as the difference in pay between males and females — is large enough to make it unlikely to occur by chance alone.
However, what is often hotly debated is the level at which multivariate regression models are calibrated. On one end of the spectrum, some people prefer to examine large sections of an employee population at once. This is called a “comprehensive approach” and may look at groups, such as all exempt employees in a country or all sales employees in a region, while controlling for all pertinent pay differentials including job family and grade level. On the other end of the spectrum is the notion that separate multivariate regression models must be used to look at many smaller job clusters. In its most extreme form at larger companies, the “granular approach” calls for potentially running hundreds of models for Similarly Situated Employee Groups (SSEGs) that can have as few as 30 people.
The table below outlines key differences between approaches at either end of the spectrum:
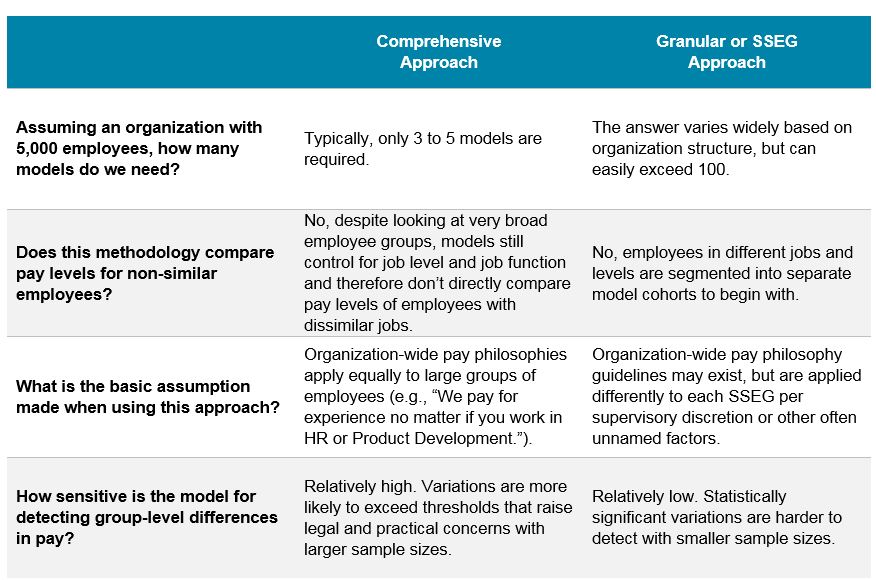
With this overview in mind, the strongest argument for using a comprehensive approach is that it is aligned with testing against existing compensation strategies. For example, written pay philosophies may state that some jobs or functions are paid above or below market, but they rarely specify that core pay drivers (e.g., pay for performance) apply to some jobs but not others.
The strongest argument for using the more granular approach is that lawsuits are typically won and lost at a more granular level. Plaintiffs tend to look at comparisons in pay within their own team or close peers, and at the same time, defendants will try to draw a very small circle around the job of the plaintiff when presenting their case. Why? It generally takes a much bigger difference in pay to show meaningful group-level differences in smaller sample sizes. Depending on the facts of the case, this approach can potentially be beneficial to either side. However, it is far less likely a granular approach will yield insights that can guide a company toward better compensation policies.
To be clear, we believe responsible parties working on any pay equity analysis need to understand the benefits of comprehensive and granular approaches alike. Additionally, there is a lot of space between an SSEG approach with 30 employees per group and an organization-wide multiple regression model. The best way to effectively calibrate between these two extremes will vary by organization type and is often the critical value-add provided by experts.
Unfortunately, we find relevant parties are too quick to pick one method over the other, often at the expensive of fully exploring the merits of more comprehensive approaches. For example, in one outlier case, a company ran a statistical analysis that excluded 90% of their workforce because it defined employee units so narrowly that only 10% of employees were deemed similar enough to be compared.
Testing the Impact of Different Methodology Choices
To examine the impact of different methodology choices on pay equity analysis outcomes, we started with a pool of data from 700 technology organizations with several million total incumbents around the globe. However, to limit the data to a more likely real-world scenario, we only sampled employees from a single sub-industry in technology in one U.S. state. We are not revealing the initial group of companies or the state in question to protect data privacy.
In the end, we ended up with a simulated technology organization with 5,000 incumbents working in one state. Our simulated company has nine functions represented. The top three functions by headcount are product development (PD) at 49.5% of the population, finance and administration (FA) at 12.1% of the population, and marketing (MK) at 12.9% of the population.
We next ran three sets of multiple regression models. To represent a comprehensive approach, we simply ran one overall multivariate regression model across all 5,000 incumbents. To represent a middle-of-the-road approach, we ran nine separate multivariate regression models for each job function. Finally, to represent a very granular (or SSEG) approach, we attempted to run 335 separate multivariate regression models for each of the unique job families in our simulated company.
In the last case, we quickly ran into the shortfalls of an SSEG approach. Only 33 job families had enough employees (30 or more) to run a valid model, and among the 33 models developed, none revealed statistically significant pay differences between men and women. Thus, almost from the start of our experiment, the SSEG approach was shown to be incapable of yielding actionable insights for our simulated company. We find this to be true for most small or mid-sized companies looking to make sustainable policy decisions.
Before reading onward, please note the figures cited below are based on a simulated organization (i.e., real randomly sampled data from employees of roughly 700 technology organizations). While illustrative of a real-world scenario leveraging a comprehensive and in-depth statistical analysis, our experiment is not representative of actual pay gaps in the technology industry or any specific company.
Pay Gap Findings for Each Model
When using a comprehensive approach, we observed a pay gap to the disadvantage of women when compared to men of 4.5% for employees “all else equal” in our simulated organization. By comparison, the middle-of-the-road approach, again looking at nine functions separately, generated a weighted average pay gap for females of 4.4% for employees in the same job levels. The unweighted average gender pay gap was 3.4%. These results are fairly close at a superficial level, but a deeper dive reveals notable differences. (See Figure 1 for more details.)
For example, using the middle approach, two functions can’t be fully assessed because they are rather small. The general management function has a large pay gap for females of 15.8%, but only 30 incumbents. As a result, the observed pay gap, while large, is deemed to be statistically insignificant. The same is true for the operations function. It also has a large observed pay gap for females of 8.4%, but with too small a sample size to make a meaningful assessment. Keep in mind, our middle approach, while far less segmented than our SSEG approach, still ran into some of the same problems ― that is, analyses using smaller sample groups rarely flag group-level pay gaps as statistically significant.
Interestingly, the middle approach showed that three functions, human resources, information technology and professional services, have small pay gaps favoring women. Analytically and practically speaking, while these three functions may not appear to present a litigation risk, it would be unwise to exonerate them from further study. Here is the key question: If pay processes are designed to produce similar results and behaviors across an organization, why do these three functions stand out? Are supervisors/leaders in these functions somehow behaving differently and use less biased judgment, or is it in fact more likely that we are seeing some random noise in the data that just happens to benefit those three functions?
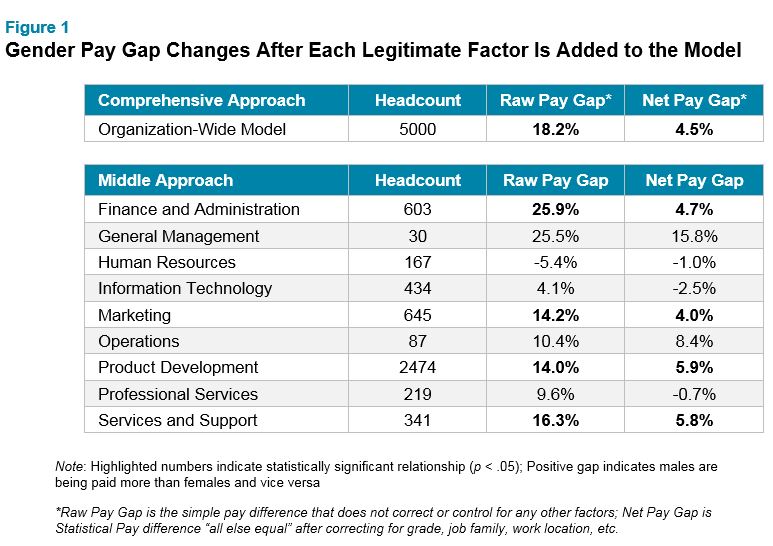
Pay Drivers of Each Model
Analytically speaking, there is only one good reason for splitting up data to run several multiple regression models: Everything is different! With that, we mean that the impact of performance, tenure, experience and grade levels on pay is different in separate parts of the organization. Even then, splitting data into pieces can be problematic because the analysis pretty much precludes any opportunity to test whether the “everything is different” assumption is actually true.
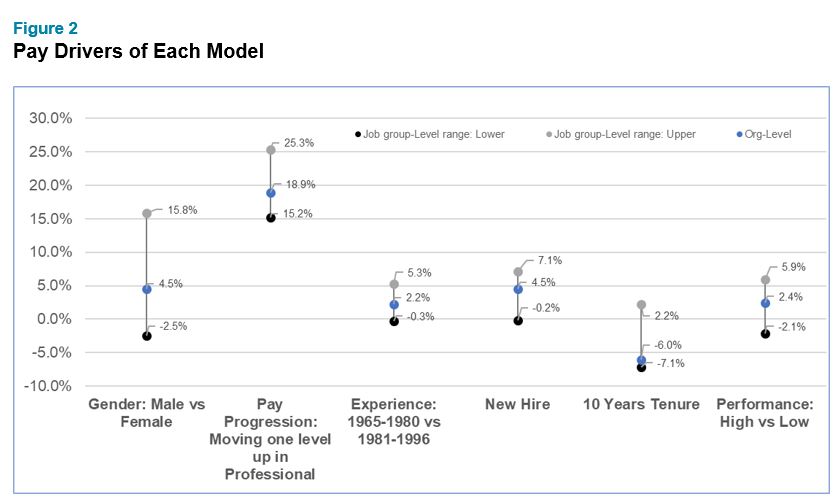
Using our data, we wanted to test if key factors driving pay are actually statistically different by job function for the simulated technology organization with 5,000 employees (See Figure 2). The results make it look as if there are differences but — statistically speaking — there aren’t. For example, at one extreme, in one function men make 2.5% less than women, and at the other extreme, men make 15.8% more than women. However, if someone would have randomly split up the data into groups, the variability would have been just as great. The same was true for pay progression, experience, new-hire status, tenure and performance. Based on those results there is no analytical reason to use the middle approach and split the data into pieces to run multiple regression analyses.
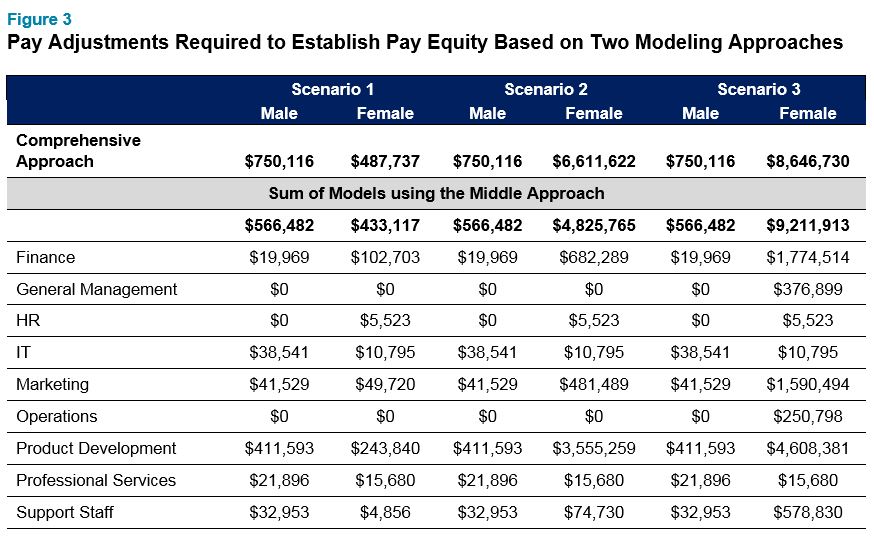
Cost of Fixing Pay Gaps Under Both Models
The most immediate and direct way to address a gender pay gap is to make pay adjustments for individual employees. The magnitude of that pay adjustment will depend on the size of the pay gap to be addressed but also on the way the models were structured. Most statisticians would know: The smaller the units designed for a pay equity analysis, the less money it takes to fix apparent pay gaps. Figure 3 confirms this in that the sum of pay adjustments suggested when using the middle approach is smaller than the pay adjustments suggested to address pay gaps using the comprehensive approach.
There are many ways to compute pay adjustments in a pay equity project and we usually start with three scenarios as outlined in Figure 3. Scenario 1 pay adjustments are designed to identify all employees who receive significantly less pay than their peers regardless of their own race or gender. The pay adjustment amounts using the middle approach is, as expected, somewhat smaller than those suggested using the comprehensive approach.
Scenario 2 adjustments are designed to bring up pay for women just enough to make sure that the pay gap is not statistically significant in each of the units created. We expected that the middle approach would require less money to achieve statistical parity and the results confirmed this ($6.6 million in pay adjustments using the comprehensive approach as opposed to $4.8 million using the middle approach). We should point out, however, that there is nothing “magical” in these results. After applying the pay adjustments using the middle approach there is still a statistically significant and fairly sizable pay gap for the overall organization. In this case it is 1.9%. So, the middle approach “got the job done” in a statistical way for each function separately, but still leaves the overall organization with a sizeable gender pay gap.
Scenario 3 adjustments are not statistical but mathematical. With that we mean that they are designed to bring the gender pay gap down to near 0% regardless of statistical significance. Because statistical significance is not a concern in this scenario, the magnitude of required pay adjustments is hardly different when comparing the Comprehensive Approach with the Middle Approach.
To sum up what we are finding here: Building more groups to build separate multiple regression models saves money but also lowers the bar for establishing pay equity!
Looking Ahead
Our analysis highlights that the way regression models are structured has a profound impact on the results of a pay equity analysis. On the extreme side, a granular approach might be sufficient to probe for immediate legal risks but realistically does not even begin to close the analytical or practical gender pay gap for the overall organization. Recall that the most granular approach required us to look at 335 separate units for the analysis and did not find statistically significant pay gaps on the group level in any one of them. So, using the extreme granular approach would have taken exactly $0 in pay adjustments to achieve pay parity while still leaving the overall organization with a 4.5% unexplained pay gap to the disadvantage of women.
The results using the middle approach is a lot closer to the results using the comprehensive approach. Still, splitting up the data into narrower units for the purpose of a pay equity analysis is equivalent to lowering the bar for achieving pay parity.
We are sometimes caught up in cost-benefit conversations where clients or legal experts question why there is a need to go beyond legal risk requirements for a pay equity analysis. More often, however, all parties acknowledge that legal risk is only one factor to direct the approach chosen for his important work.
Most of the time we recommend erring on the somewhat broader side when calibrating pay equity models for the following reasons:
- A comprehensive model is closely aligned with existing pay philosophies that are defined broadly for the whole organizations rather than by job functions or job families. Please note that simply paying above or below market for some jobs is not a sufficient analytical reason for separate regression models – such differences can easily be accommodated in one comprehensive model.
- In the age of greater transparency around employee compensation, a comprehensive model simplifies the messaging to employees as to what it is you are paying for (e.g., Do we pay for performance? How much? What is our overall gender pay gap? Do we reward supervision? And so forth). Rather than developing different stories for different jobs families or function, your story can align with your pay equity approach by simply communicating one pay strategy for a whole country or business unit. We think that this is actually quite consistent with how our clients practically think about their rewards.
- Finally, our experience and an analysis of the data shown here teaches us that fixing pay gaps on the basis of a broadly calibrated comprehensive model also fixes gaps for smaller units while a more granular analysis may not sufficiently address pay gaps for broader units. This is important because plaintiffs and government agencies often run their own analysis and may not share the same point of view on how to structure the data. With a comprehensive model you are basically covering all bases.
The final point we’d like to make is that a pay equity analysis should follow compensation practice — not the other way around. If you start building “shadow” job structures specifically for the purpose of a pay equity analysis that do not exist in your source systems and are unknown by managers and employees, you are probably taking your efforts a little bit too far.
If you would like to learn more about conducting a pay equity analysis or have questions about this topic, please contact one of the authors or write to [email protected].
Related Articles